
This week’s Sunday Column is guest edited by Andy Marston.
Full Disclosure: He is a young man that I stole from the sports agency world, to work at one of our AI investee companies: Zone7. In the last 3 years he has become the leading sports thought leader of his demographic. And an expert on AI.
He came to us with this insight below, and we loved the vision, as it applied to what we do at Albachiara and AYNE. But the IP of the article is his. So, over to him. Horse’s mouth and all that.
If this article doesn’t make you think, then be a bit worried.
Buona Pasqua
Ren-AI-ssance
Using AI to turn AYNE into a sports MBA
Last week, I fed ChatGPT the Albachiara Sunday Column on sport’s ‘B2B apple’; gave it a few additional prompts for context, and asked it to use the article to evaluate if Manchester United was over or undervalued at £5bn.
The result was… Not bad.
Here’s an excerpt.
“Founder of Albachiara, Roger Mitchell, notes that if Manchester United FC was considered a B2C business, it would be re-rated as such, the same way tech companies are in Silicon Valley: per user.
By making this shift from a B2B to a B2C model, sports organizations can develop a better understanding of their fans, create tailored solutions that resonate with them, and ultimately increase their lifetime value (LTV) compared to customer acquisition costs (CAC). This would lead to higher valuations and a more sustainable business model.”
Ultimately, AI is only as good as what you feed it. GIGO (garbage in, garbage out) is a common concept within computer science, where the quality of output is determined by the quality of the input, including the level of context provided. So, if I’ve only fed it one article and asked it to reason around the valuation of Manchester United, you could understand why that reasoning may have some flaws. And there are certainly some flaws in the article that it spat back out to me.
La Biblioteca Medicea
(The Laurentian Medici Library)
However, what if, instead of feeding it one solitary article, you could feed it the entire back catalogue of AYNE, which has recorded hundreds of episodes and thousands of hours of opinion?
Well, it turns out that some folk, much smarter than myself, have already done this for a number of the most popular podcasts in the world. Take The Huberman Lab podcast, for instance. Hosted by neuroscientist and tenured professor Dr Andrew Huberman Ph.D, the podcast discusses science and science-based tools for everyday life. As the most popular health and fitness podcast in the USA, many people have learned a lot from it. But, as is the case for a lot of great podcasts, the episodes are long, and if you have a specific question related to something that has been covered previously, it’s a pain to go back and try to find the answer. Just like walking into the Laurentian Medici Library and trying to find a literary needle.
This led Dan Shipper, the CEO of Every, to devise a solution: a Huberman Lab chatbot using OpenAI’s GPT-3, as explained in this article.

This tweet thread explains even better.
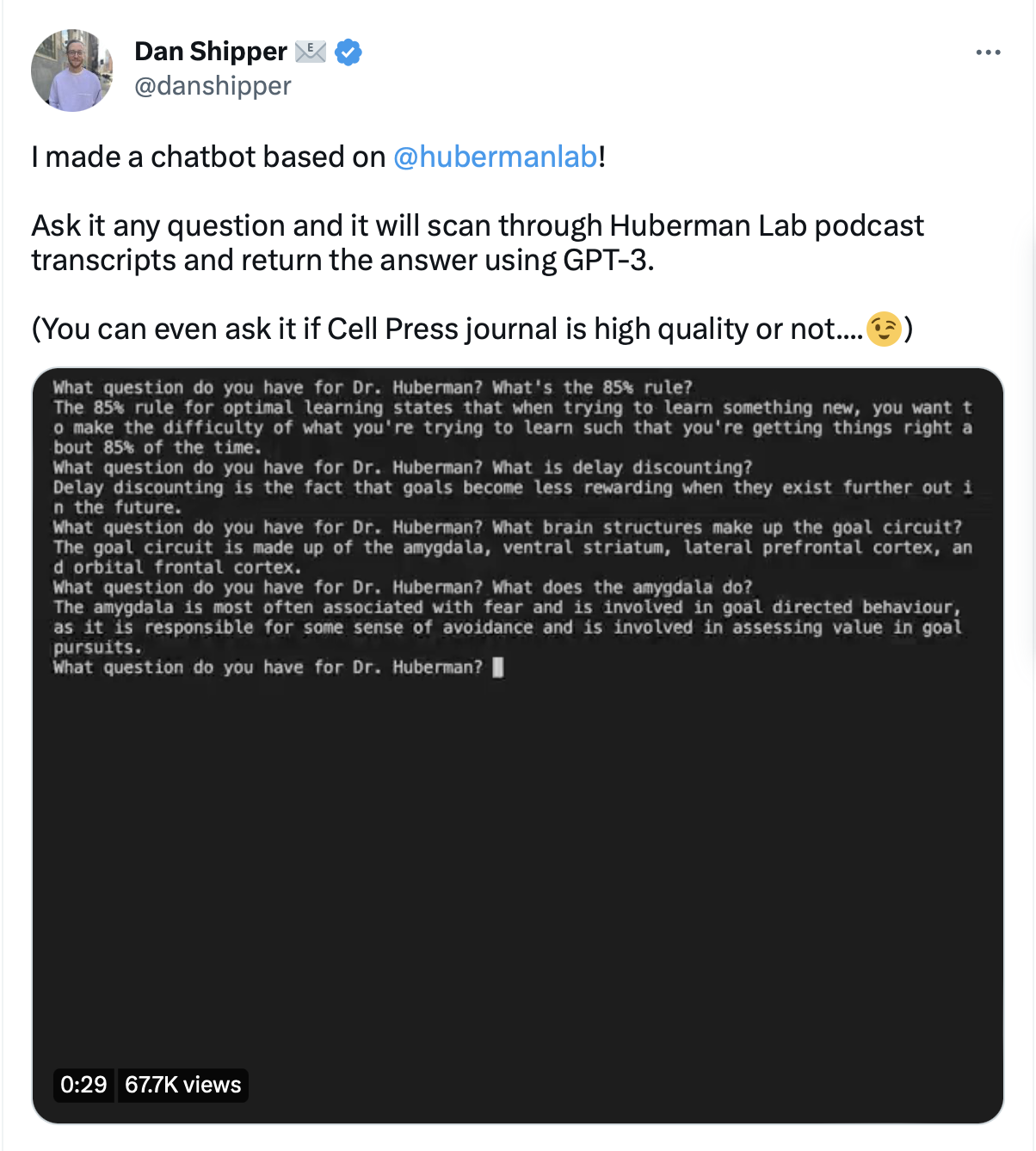
Taking a weekend to build, the chatbot could answer questions about topics that the podcast had covered in the past, plausibly well.
How?
Well, without wanting to get overly technical, the principles of the model are laid out as follows.
- It ingests and makes searchable all the transcripts from the Huberman Lab podcasts.
(Transcripts were likely made using an AI tool, such as Whisper or riverside.fm)
- When a user asks a question, it searches through all the transcripts it has available, and finds sections that are relevant to the query.
- Then, it takes those sections of text, and sends them to GPT-3 with a prompt that looks something like:
Answer the question as truthfully as possible, using the provided context and, if the answer is not contained within the text below, say “I don’t know.”
Essentially, it provides GPT-3 access to the transcripts of old episodes and asks for them to be used as the sole information source when providing an answer.
This model worked well, but not always. Shipper notes that the bot is subtly wrong often; or it is not specific enough.
It’s easy to dismiss this technology, given these shortcomings, but most of them, however, are immediately solvable.
The answers will get a lot better if I clean up the data used to generate them. Right now, they’re based on raw transcripts of podcast episodes. When humans talk, they don’t tend to talk in crisp sentences. So the answers to a lot of the questions I might ask, are spread out around the episode and aren’t clearly spelled out in the transcript. If I cleaned up the transcripts to make sure that, for example, every term was clearly defined in a single paragraph of text, it would make for much better answers.
Shipper also suggests that, with additional time spent on the model, he could create a filter where it essentially asks the chatbot to check its own working, before returning an answer to the end user. This will get infinitely more powerful once GPT-3 can access the Internet.
It could also be designed to work on semantic meaning, not just keywords (using a concept called vector embedding). This allows you to search for a term like “neurotransmitters” and get results that include “dopamine” and “serotonin.”
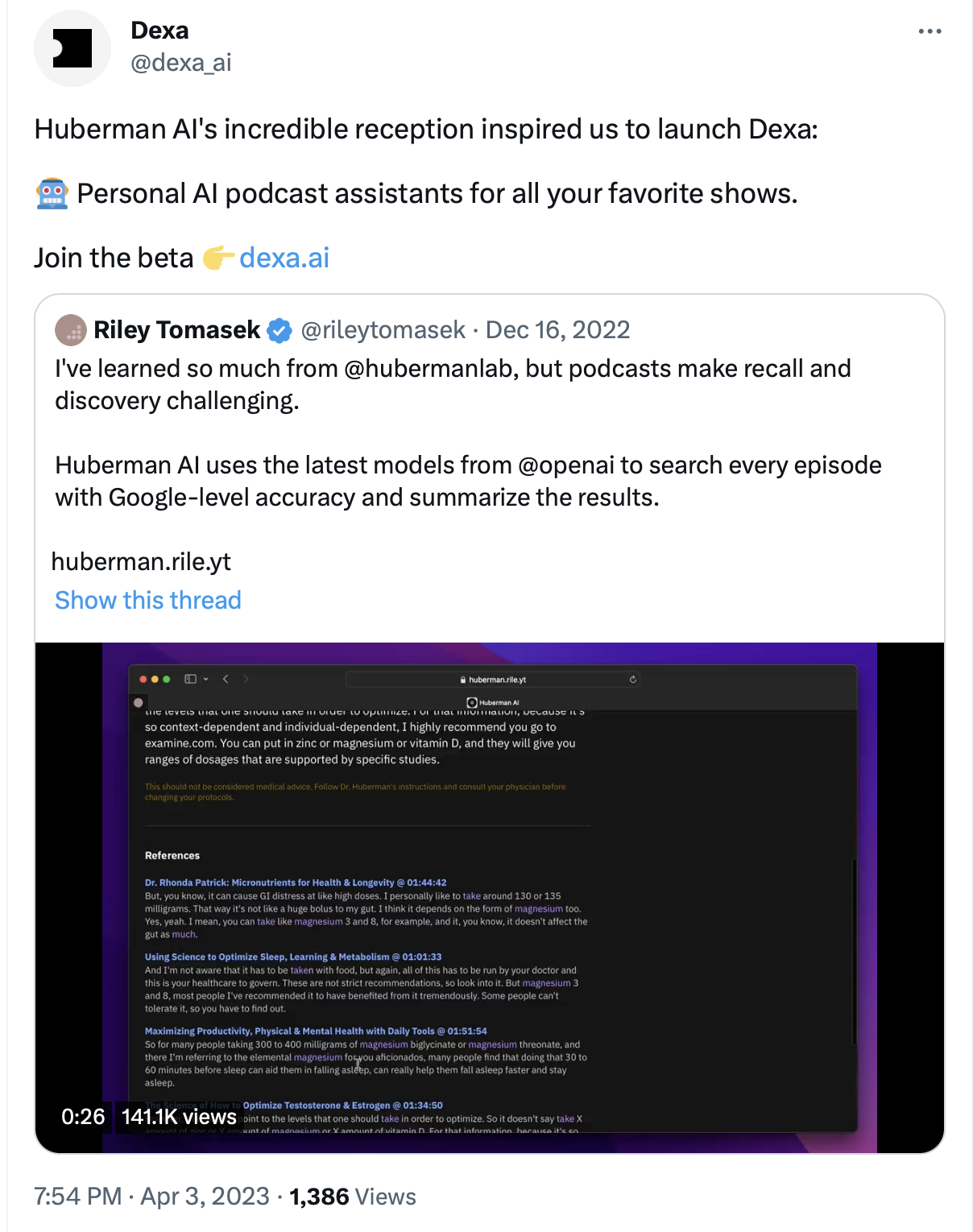
This is what Riley Tomasek, a former software engineer, did when he launched his own solution, Huberman AI, at around the same time.
Using OpenAI, Tomasek’s creation worked to allow the end user to search every episode with ‘Google-level’ accuracy and even summarize the results.
Given the huge popularity of the project, Tomasek has recently launched dexa.ai, applying his same process to several other popular podcasts, including Lex Fridman’s podcast and The Jordan Harbinger Show. See this tweet thread.
“>
The future of knowledge transfer
Described as a ‘personal AI podcast assistant for all your favourite shows’, dexa.ai has huge potential to completely reinvent how we, with perhaps the exception of Italy, consume content, i.e. via chatbots.
Being able to convert huge bodies of text (written or audio), and use them to model a chatbot, will be a huge deal for both content creators and content consumers. They will not only have access to copious amounts of information, but also the ability to filter from whom they wish to receive this information.
For consumers it is likely that, in the future, you will turn to a chatbot rather than a generic search engine for answers.
Google and Microsoft both recognise this.
Additionally, these chatbots could soon hold all the knowledge shared within any and every podcast, and be capable of answering from the perspective of those same specific individuals (who have provided enough sample content).
This means that, if I want to ask Albachiara to review an issue for my sports tech start-up, or ask for Roger’s opinion about whether Man United is over or undervalued, but I have no relationship or connection to him, no problem!
Or, if I want to know what Dr Huberman recommends as the ideal morning routine to maximise my productivity, again, consider it done.
With the recent plugins, that have been released from companies such as Expedia and Instacart, these commands could even go a step further. For example, buying products and booking services (on your command) based on the answer.
This is not science fiction. It is happening anon.
There are obvious interesting business opportunities for the sports industry, with its high levels of knowledge sharing.
For content creators, this is a new way to monetise any existing set of intellectual property.
You would struggle to charge consumers for access to the back catalogue of AYNE, as it is a freely available podcast. However, if it was reformatted into a chatbot, which could instantly answer questions around the sports industry, there’s a good chance people would pay a fee or subscription.
In the hands of someone asking the right questions, AYNE could become their very own sports business MBA, or even a virtual advisor for their business.
The same is true for so many other podcasts, newsletters, and vlogs across a whole spectrum of other content topics, too.
There are currently hundreds of thousands of (potentially copyrighted) bodies of text, audio, and video that could be turned into chatbots. All that is required is someone willing to make them (and legal permission to do so).
The world of executive training, insight selling, and general consultancy is about to change.
Listen to our “Are you not entertained?” sports management podcast here.
Let us also recommend our wonderful colleague John WallStreet. His daily newsletter here is essential reading, especially in its coverage of the US market. For lovers of sports data, this is a great read.
“RAR is a play on Wins Above Replacement (WAR)–the most well-known advanced metric used in sports. The origins of WAR trace back to Bill James in the 1980s, but it was made famous by Michael Lewis’ 2003 book Moneyball (and even more famous by its blockbuster movie release in 2011).”
To find out what we do in change management, have a look here.
For our C-suite management services, read here.
Here you can know more about our content development work.
Discover our Corporate Learning service.
Get to know more our “Sport Summit Como” yearly sports management event here.
If you are interested in our own story, check us out here.